Azure's Datenbank-Dienste und Daten-Services in der Cloud
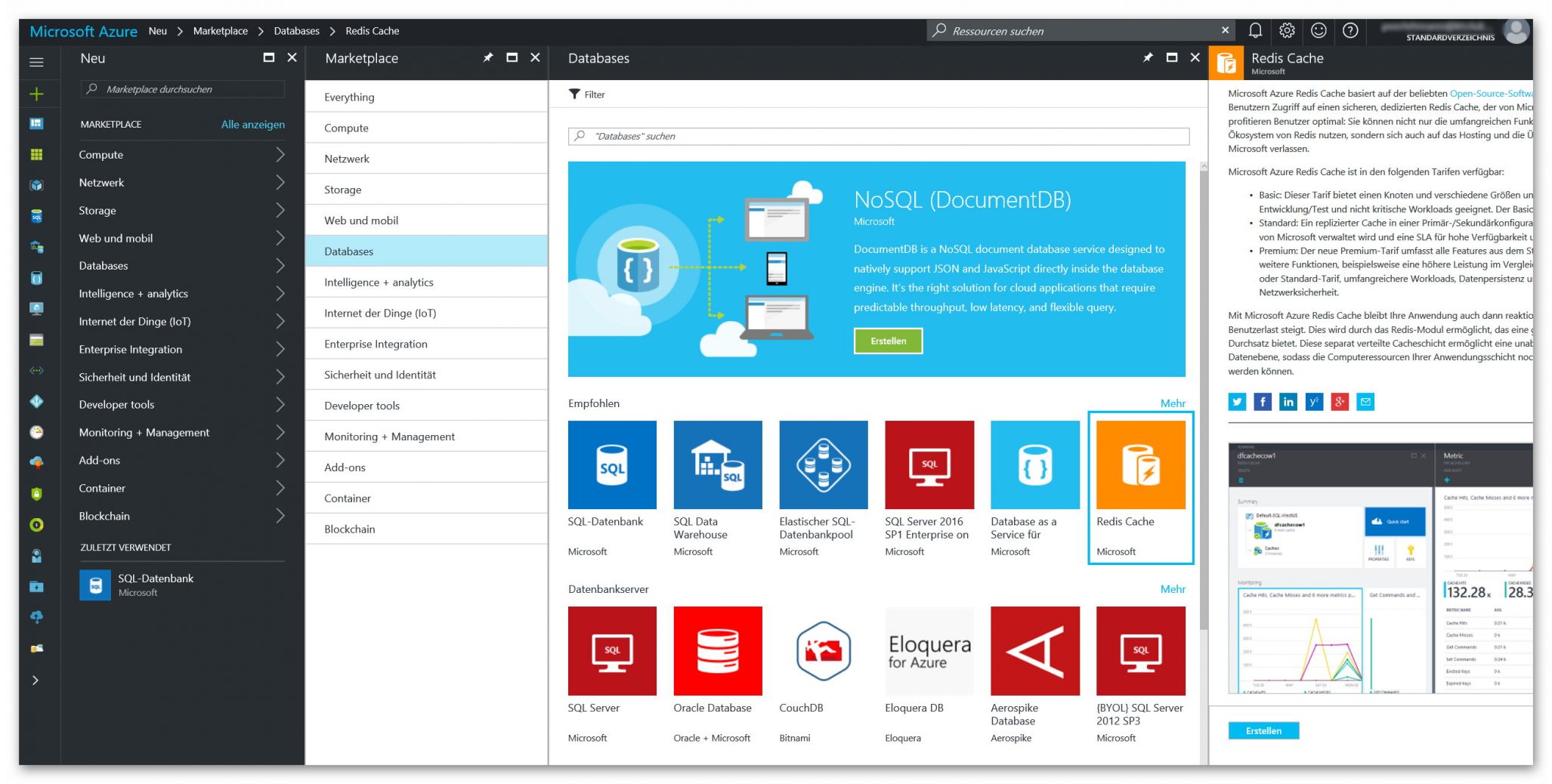
Die Dienste und Services der Microsoft Cloud Azure sind inzwischen sehr vielseitig und ihre Anzahl ist stark angewachsen.
Eine mittlerweile dreistellige Anzahl an Services und Diensten, die allein Microsoft in seiner Cloud Azure bereitstellt. Eine mittlerweile vierstellige Anzahl an Services und Diensten, die in Azure angeboten werden, wenn man die Produkte von Partnern und Drittanbietern mitrechnet. Schwer hier den Überblick zu behalten. Daher wollen wir hier etwas Licht ins Dunkel mit der folgenden Übersicht bringen.
Natürlich können und möchten wir hier nicht mit einer kompletten Auflistung aller Azure Dienste langweilen. Daher sollen zunächst nur die Daten und Datenbank relevanten Dienste, die von Microsoft selbst angeboten werden, berücksichtigt werden.
Und dies in einer groben Unterteilung in Dienste und Services für „Datenbanken“ - also DaaS - und „Daten und Analytics“.
DaaS/DBaaS: Datenbanken als Service in der Cloud
• Azure SQL Datenbank

Die relationale SQL-Datenbank als DaaS-Lösung (Database-as-a-Service)
Sozusagen die „klassische“ relationale SQL-Server Datenbank, nur eben „ohne“ Server sondern als Service in Azure bereitgestellt. Mit allen Vor- und Nachteilen einer Cloud-Datenbank im Vergleich zu On-Premise. Skalierbar in detaillierten Stufen in Leistung und Größe, relativ preisgünstig und aufgesetzt in Minuten: „Stell Dir vor, es ist Datenbank und keiner installiert!“
Natürlich auch mit allen Nachteilen, wie dem Fehlen des voll vorhandenen Datenbankserver mit all seinen Diensten, wie SQL-Browser und Agent. Die klassische Diskussion zwischen Cloud und eigenes Blech soll hier aber nicht angerissen werden, sondern möchten wir ja auf die weiteren Datenbank-Dienste der Azure-Cloud eingehen.
• Azure-Datenbank für MySQL

Eine MySQL-Datenbank als Dienst bzw. Service
Die relationale Open Source Datenbank MySQL als Datenbankdienst in Azure, basierend auf der MySQL Community Edition. Also auch eine DaaS-Lösung mit vollständiger Verwaltung in Azure bezüglich Leistung, Skalierbarkeit, Verfügbarkeit und Datenschutz.
Verschiedene Preismodelle, von Basic über Standard und demnächst auch Premium, gestaffelt nach Compute Units und Storage-Space stehen zur Verfügung.
• Azure-Datenbank für PostgreSQL

Eine PostgreSQL-Datenbank als Dienst bzw. Service
Analog zur Azure-Datenbank für MySQL, ist dies die relationale Open Source Datenbank PostgreSQL als Datenbankdienst in Azure, ebenfalls basierend auf der Communityversion. Also auch eine DaaS-Lösung mit vollständiger Verwaltung in Azure bezüglich Leistung, Skalierbarkeit, Verfügbarkeit und Datenschutz mit vergleichbaren Preismodellen wie bei der Azure-Datenbank für MySQL.
Verbindungsbibliotheken stehen derzeit für Python, PHP, Ruby, .NET, Java, Go, Node.js, ODBC, C und C++ zur Verfügung. Der Dienst unterstützt die Installation von PostgreSQL Erweiterungen nur teilweise und keine eigenen Erweiterungen. Was sich aber noch jederzeit ändern kann, da der Dienst sich noch in der Preview-Phase befindet. Ebenso werden noch nicht alle Verwaltungsmerkmale in der Skalierung, Migration und bei Versionsupgrades unterstützt.
• SQL Data Warehouse
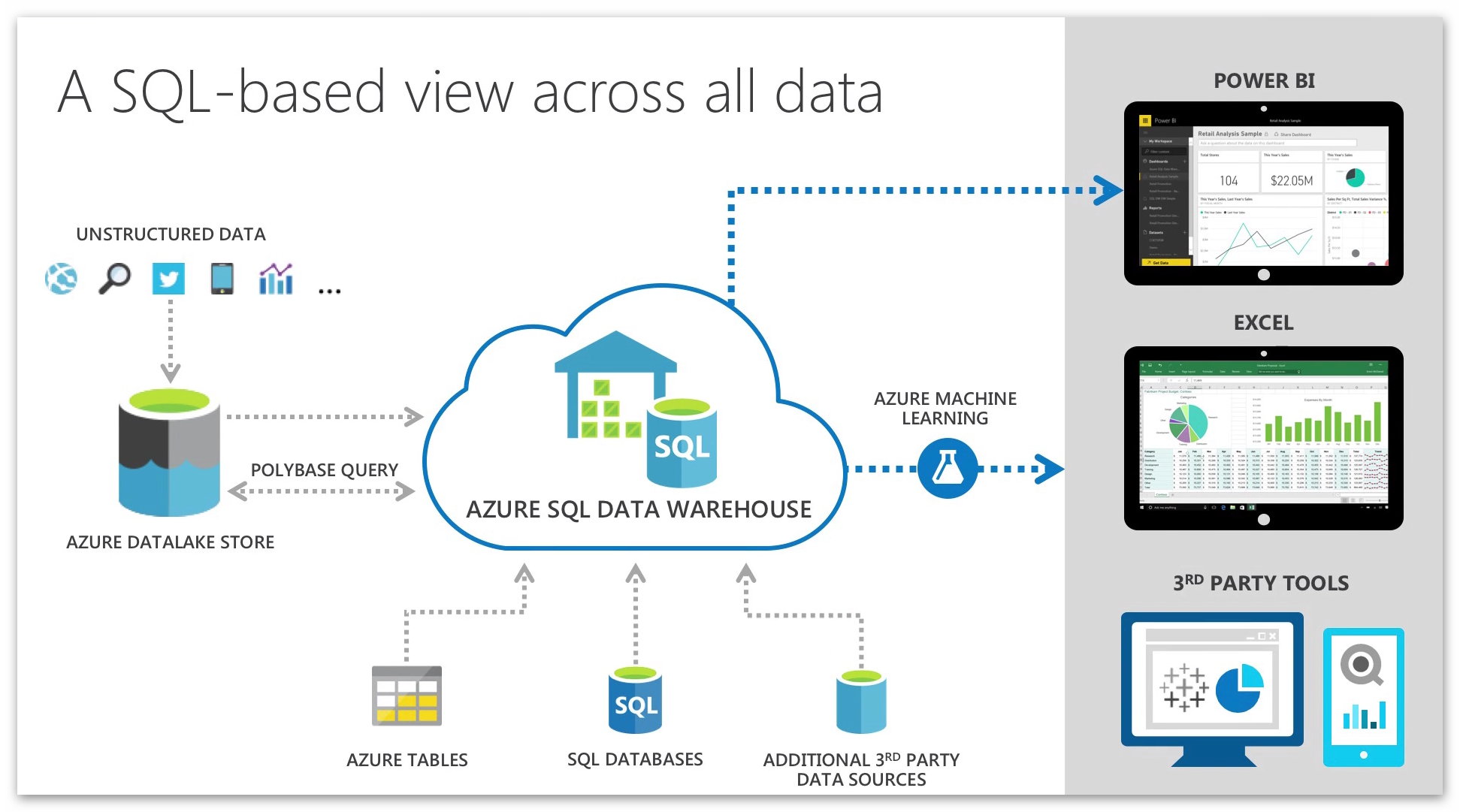
Eine elastisch skalierbare Data Warehouse Lösung als integrierter Service mit Enterprise-Funktionalitäten
Die Basis für das SQL Data Warehouse ist (wie nicht anders zu erwarten) die SQL-Server Datenbankengine. Daher stehen auch viele - aber nicht alle! - bekannten Eigenschaften und Funktionen, wie die Verwendung von T-SQL, Stored Procedures, User Defined Functions, ColumnStore-Indizes usw., zur Verfügung.
Die Architektur ist auf MPP (Massively Parallel Processing) mit hoher Skalierbarkeit auch für Big Data Anwendungen ausgelegt. Die „elastische“ Skalierbarkeit bedeutet hierbei, dass getrennt nach Compute- und Storage-Leistung skaliert werden kann.
Interessant wird der Data Warehouse-Dienst über die Integration in die Azure-Plattform und Kompatibilität mit den SQL Server Tools. Dies ermöglicht ein sehr leistungsfähiges Zusammenspiel der Azure-Dienste wie Azure Data Factory, Stream Analytics, Machine Learning oder PowerBI. Und dies mit den Werkzeugen und Diensten wie Analysis Service, Integration Service, Reporting Service und insbesondere PolyBase und dem Azure Data Lake Store zur Integration von hybriden Datenquellen (NoSQL, Blob- und Hadoop-Speicher, Filestores etc.).
Die Verwaltung kann daher auch mit den bekannten Werkzeugen wie dem SQL Server Management Studio oder Visual Studio mit den SQL Server Data Tools oder im Azure Portal bzw. Dashboard erfolgen.
• SQL Server Stretch-Datenbank
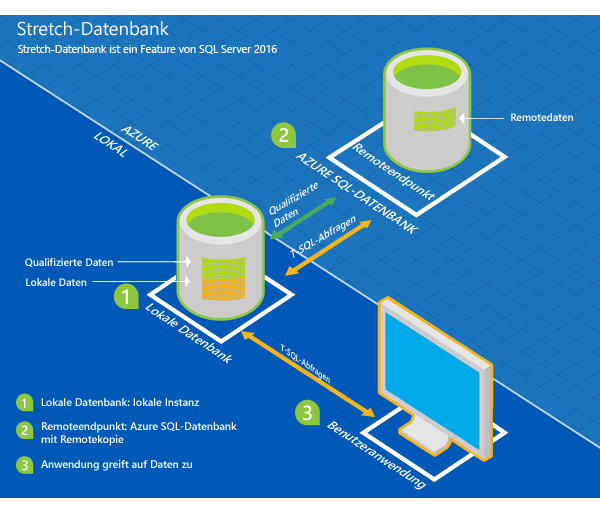
SQL Server-Datenbanken dynamisch nach Azure erweitern
Die SQL Server Stretch-Datenbank ermöglicht es vollkommen transparent, cold und warm data nach Azure auszulagern. Transparent bedeutet hierbei, ohne notwendige Anpassungen der Applikationslogik oder von Abfragen oder Views.
Welche Daten nach Azure ausgelagert werden sollen (also wie kalt oder warm sie sein sollen) wird in Form von Filtern definiert, wie zum Beispiel „Alle Daten älter als …“. Die Aktivierung und Verwaltung einer Stretch-Datenbank ist einfach und schnell mit den Standardwerkzeugen (SSMS, Azure Portal/Dashboard) möglich. Die Sicherheitsfunktionen des SQL Server wie Always Encrypted oder Row Level Security werden auch von einer Stretch-Datenbank unterstützt.
Auf den ersten Blick scheint die Funktion einer vollkommen transparenten Stretch-Datenbank sehr nützlich. Einige Einschränkungen bei der Verwendung - einige Tabelleneigenschaften und Datentypen verhindern derzeit den Einsatz - sowie die im Vergleich zu anderen Azure Diensten überraschend hohen Kosten, verhindern derzeit jedoch (noch?) oft den Einsatz.
• Azure Cosmos DB
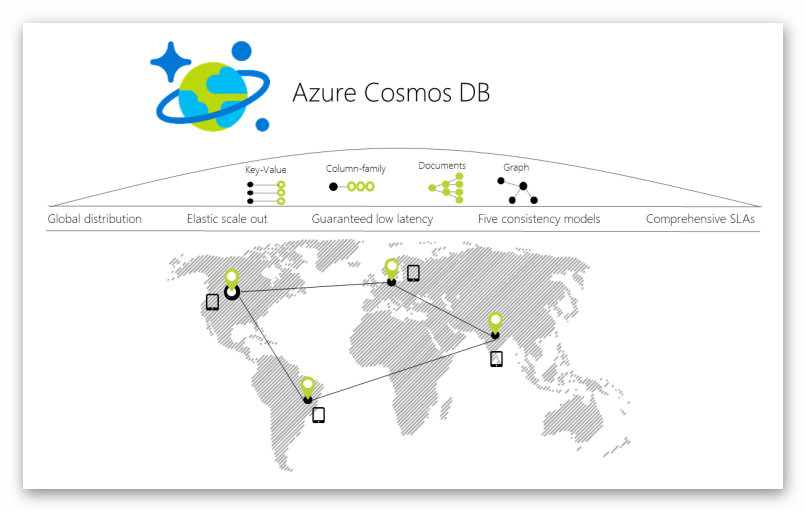
für global verteilte Datenbanken mit verschiedenen Datenmodellen
Als Nachfolger der Document-DB ist die Azure Cosmos DB einer der neuesten Azure Services. Hauptmerkmale der Cosmos DB sind die hohe Verfügbarkeit und weltweite Skalierbarkeit bei Unterstützung von verschiedenen Datenmodellen. Es werden verschiedene Leistungsmerkmale wie Antwortzeiten, Verfügbarkeit, Durchsatz und Konsistenz via SLAs garantiert. Die Leistungsfähigkeit wird durch eine einfach zu erstellende, globale und redundante Verteilung der Daten erreicht, wobei eine Azure-Region als Schreibspeicher definiert wird und beliebig viele andere Regionen als Lesespeicher.
Als Datenmodelle werden derzeit No-SQL Daten für Dokumente, Diagramme (Graph-Data), Schlüssel-Wert-Paare (Key-Value), Tabellen und Spaltendaten (Column-Value) unterstützt. Hier ist demnächst noch mehr zu erwarten.
Verschiedene konfigurierbare Konsistenzmodelle bieten ein breites Spektrum an hoher SQL-ähnlicher Konsistenz bis hin zu NoSQL-ähnlicher Konsistenz. Konzipiert für hohe Anforderungen an Leistung und Verfügbarkeit für u.a. IoT, Industrie 4.0 und global verteilte Mobile Apps und Anwendungen, ist mit einer entsprechend dynamischen Weiterentwicklung von Cosmos-DB in der Zukunft zu rechnen.
• NoSQL Tabellenspeicher
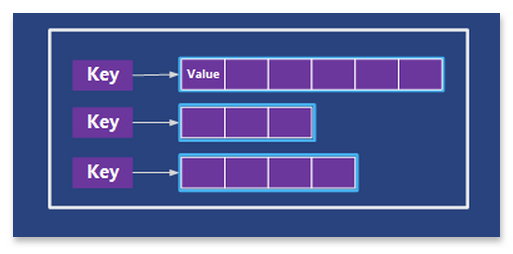
Schlüsselwertspeicher für teilweise strukturierte Datasets
Unter dem Sammelbegriff Azure Storage werden Services angeboten, um verschiedene Arten von Daten in der Cloud zu speichern. Dies sind zur Zeit BLOB bzw. Objekt Daten, Messaging-Queues, File Shares und NoSQL Tabellenspeicher. Diese Speicher sind für massive Skalierbarkeit, Erreichbarkeit und Verfügbarkeit ausgelegt. Kosten entstehen jeweils nur für den verwendeten Speicherplatz. Es werden Schnittstellen für die meisten und gängigsten Sprachen sowie das REST API unterstützt. Für einen hohen Workload wird eine Premiumvariante angeboten.
Der im weitesten Sinne hier als Datenbankdienst verstandene „Table Storage“ unterstützt das Speichern von strukturierten und teilweise strukturierten Datasets in Form eines NoSQL Key-Attribute Speichers.
Eine Tabelle ist hierbei eine Sammlung von Entitäten, die keinem Schema unterliegen müssen. Das bedeutet, dass eine einzelne Tabelle Entitäten mit verschiedenen Eigenschaftensätzen enthalten kann.
Der NoSQL Table Storage wird zunehmend durch die Table API der Cosmos Datenbank (siehe dort) abgelöst werden, die ebenfalls einen Table Storage bereitstellt.
• Azure Data Factory
Datentransformationen und Transfers orchestrieren und verwalten
Die Azure Data Factory (ADF) sind mindestens einen eigenen Artikel wert. Sie sind als eine Art SSIS für die Cloud Azure anzusehen und bilden zusammen mit anderen Diensten wie zum Beispiel PolyBase umfangreiche Möglichkeiten und Ansätze, wenn es darum geht, irgendwelche Daten von irgendwo nach irgendwo zu transferieren und dies mit oder ohne Transformationen, Auswertungen oder Intelligenz.
Unter der Einbindung der verschiedensten Azure Daten Services lässt sich die ADF im Vergleich zu klassischen ETL-Strecken etwas mehr als „Extract and Load and then Transform“ (ELT) Plattform verstehen.
Mit der ADF lassen sich datengetriebene Workflows, hier Pipelines genannt, mit Aktivitäten, hier Activities (data movement und data transformation activities) verknüpfen und verwalten. Datenquellen und Senken können hierbei die Azure Datenquellen aber auch viele On-Premise Datenquellen in Form von Datenbanken, NoSQL, File basierten und generischen http oder ODBC Datasets sein, um nur einen Teil zu nennen.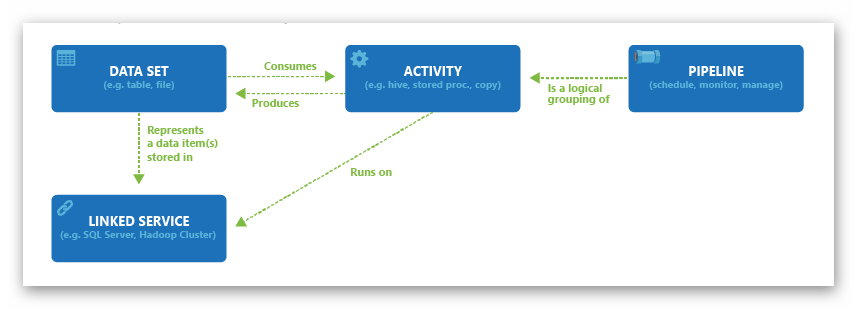
Als Aktivitäten lassen sich die Dienste rund um Hadoop – hier in Form von Azure HDInsight – wie auch Stored Procedures (Azure SQL und SQL Server) und weitere einsetzen. Somit lassen sich recht komplexe Szenarien über das Zusammenspiel von Datasets, Aktivitäten, Pipelines und Linked Services abbilden. Die Möglichkeiten scheinen zunächst fast unbegrenzt und werden auch kontinuierlich ausgebaut.
Data & Analytics - Daten und Analysen
Überblick der Data & Analytics-Services in der Microsoft Cloud Azure
Im Folgenden werden einige von Microsoft angebotene Dienste und Services zum Thema "Daten und Analysen" kurz vorgestellt:
- HDInsight
Cloudbasierte Hadoop-, Spark-, R Server-, HBase- und Storm-Cluster - Machine Learning
Predictive Analytics-Lösungen erstellen, bereitstellen und verwalten - Stream Analytics
Echtzeitverarbeitung von Datenströmen von Millionen von IoT-Geräten - Data Lake Store
Riesiges Repository für Big Data-Analyseworkloads - Data Lake Analytics
Verteilter Analysedienst zur vereinfachten Analyse von Big Data - Azure Analysis Services
Datenanalysen in der Cloud - Azure Data Catalog
Verwalten von Unternehmensdatenbeständen
Überblick, soll aber auch hier bedeuten, dass nur die wichtigsten und von Microsoft selbst angebotenen Dienste berücksichtigt werden. Dies sind zum einen Dienste zu Data bzw. Big Data, bei Microsoft steht der Begriff „Data Lake“ für Big Data, und Dienste zu Analysen und Auswertungen. Zu Data Lake, also den Diensten zu Big Data sortieren sich demnach die Dienste „Data Lake Store“ und „Data Lake Analytics“ sowie HDInsight ein.
Jeder einzelne hier aufgezählte Service könnte locker einen eigenen Artikel oder ganze Bücher füllen. Es sei nochmals darauf hingewiesen, dass die Entwicklung in und für Azure – auch wegen Microsofts Devise „Cloud first“ – sehr dynamisch ist und daher der Überblick nur ein zeitliches Abbild geben kann. Die Verfügbarkeit in der besonders verwalteten Azure-Region in Deutschland wird zum Beispiel noch zunehmen sowie einzelne Funktionen und Kompatibilitäten sowie die Integration der Dienste.
• HDInsight - Apache Big Data und Analyse - Hadoop and more
Cloudbasierte Hadoop-, Spark-, R Server-, HBase- und Storm-Cluster
HDInsight bringt die bekannten Apache Open Source Big Data und Analyse-Technologien wie Hadoop, Spark, Hive, MapReduce, HBase, Storm und Kafka, sowie den Microsoft R Server in die Microsoft Cloud.
HDInsight basiert auf einer Distribution der Hadoop-Komponenten der Hortonworks Data Platform (HDP). HDInsight wird in verschiedenen Clusterversionen angeboten, die die verschiedenen HDP-Versionen von 2.1 bis aktuell 2.6 abbilden, die unter Linux und Windows implementiert sein können. Die Implementierung unter Windows läuft allerdings aus und neue Versionen und Updates werden nur noch unter Linux angeboten.
Mit einer SLA von 99,9 % und Support rund um die Uhr, ist HDInsight mit verschiedenen Replikationsmethoden für vollständige Redundanz und hohe Verfügbarkeit und Ausfallsicherheit ausgelegt.
Über die getrennte Belegung von Storage und Compute-Leistung, lässt sich der Dienst, je nach Workload, angepasst und kosteneffizient skalieren. Allerdings verursacht ein einmal eingerichteter Cluster zeitabhängige Kosten, ob er genutzt wird oder nicht. Der Dienst HDInsight steht auch in der besonders verwalteten Azure-Region in Deutschland zur Verfügung.
• Machine Learning - Predictive Analytics und Data Science
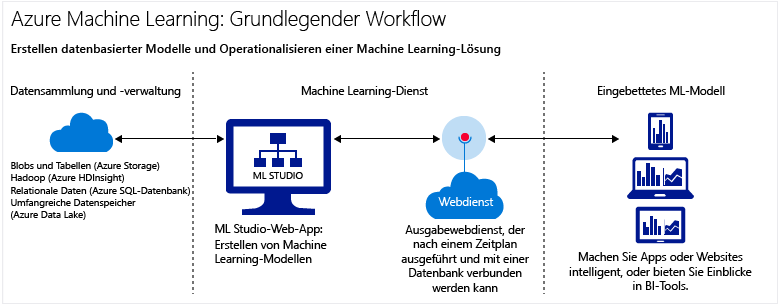
Cloudbasierte Predictive Analytics-Lösungen erstellen, bereitstellen und verwalten
Mit Azure Machine Learning (AML) stellt Microsoft einen cloudbasierten Dienst für Predictive Analytics und Data Science Anwendungen bereit. Bereitgestellt wird, neben dem eigentlichen Dienst, eine große Algorithmenbibliothek, eine Studio-Komponente zum Entwickeln, Testen und Verfeinern von Modellen sowie eine einfache Möglichkeit, die erstellten Modelle als Webdienst zu veröffentlichen.
Herzstück ist das AML Studio, in dem die Vorhersagemodelle relativ schnell erstellt, getestet, operationalisiert und verwaltet werden können. Das Studio bietet eine umfangreiche Bibliothek mit Machine Learning-Algorithmen und -Modulen, sowie viele Beispielexperimente und R- und Python-Pakete. Unterstützt werden auch benutzerdefinierten R- und Python-Skripte.
Über das Studio werden die Modelle als Webdienste veröffentlicht, so dass sie von benutzerdefinierten Apps oder BI-Tools genutzt werden können.
Zum Testen oder Ausprobieren steht zur Nutzung des Studios eine kostenlose Version mit eingeschränkten Funktionalitäten bereit. Sonst wird nach Benutzer pro Monat und Zeit berechnet. Für die Veröffentlichung der Modelle, oder hier Experimente genannt, die über einen Webdienst bereitgestellt werden, sind verschiedene Tarife verfügbar. Und, der Dienst wird auch in der Deutschland-Cloud mit entsprechender Datenhoheit und zusätzlichen Sicherungs- und Datenschutzstufen angeboten.
• Stream Analytics - Echtzeitverarbeitung von Datenströmen
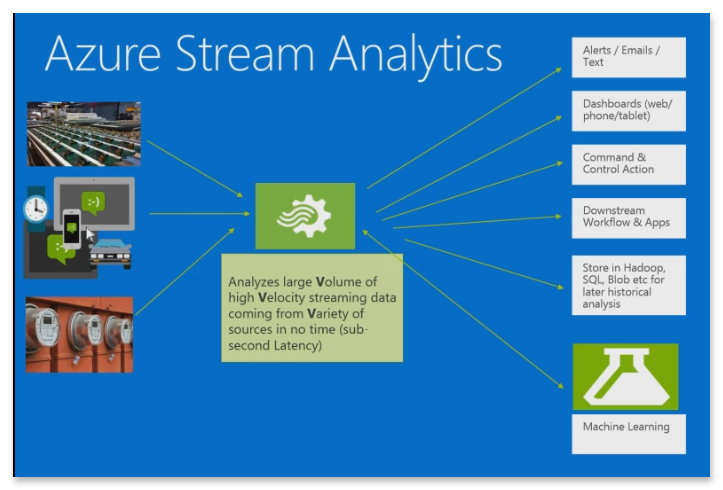
Analytics-Lösungen in Real-Time für die Cloud
Real Time Analytics für Streamingdaten designet für IoT/IIoT – so ließe sich der Dienst Azure Stream Analytics am kürzesten beschreiben. Vergleichbar der Analyseplattform Apache Storm, welche ja auch über HDInsight in Azure angeboten wird, ist Stream Analytics als PaaS-Lösung verfügbar.
Als Quelle mit Streamingdaten für Stream Analytics kann ein Azure Event Hub oder IoT Hub direkt verwendet werden. Die Daten können aber auch aus einem Datenspeicher, wie z.B. einem Azure Blob Storage, abgerufen werden.
Zum Untersuchen des Datenstroms lässt sich ein Stream Analytics-Auftrag erstellen, in dem angegeben ist, woher die Daten stammen und wie nach Daten, Mustern oder Beziehungen gesucht werden soll. Für diese Aufgabe unterstützt Stream Analytics eine SQL-ähnliche Abfragesprache, mit der sich die Streamingdaten für einen bestimmten Zeitraum filtern, sortieren, aggregieren und zusammenführen lassen.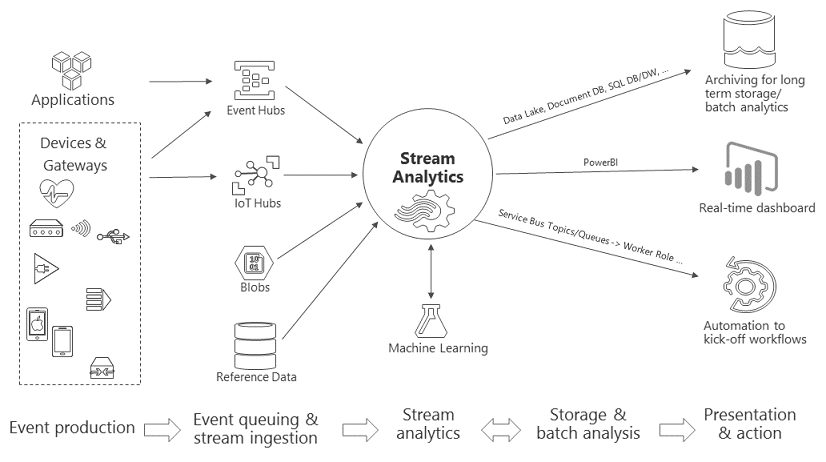
Schließlich ist im Auftrag auch noch der Ausgabeort angegeben, an den die transformierten Daten gesendet werden. So lässt sich steuern, was als Reaktion auf die analysierten Informationen zu tun ist. Beispielsweise können Warnungen ausgelöst, Informationen an ein Berichtstool wie Power BI geschickt oder Daten zur späteren Untersuchung gespeichert werden.
Gegenüber der oben erwähnten Analyseplattform mit Apache Storm ergeben sich für Stream Analytics ein paar Vorteile, wie die bessere Integration in Azure, die verwendete Abfragesprache mit einem Subset von T-SQL und letztendlich die Kostenstruktur, da der Dienst nutzungsbasiert auf Grundlage der Menge an verarbeiteten Ereignissen und dem Umfang der im Cluster bereitgestellten Rechenleistung abgerechnet wird, und nicht für den bereitgestellten Cluster wie bei HDInsight bzw. Apache Storm.
Stream Analytics wird mittlerweile auch in der Deutschland Cloud von Microsoft angeboten.
• Data Lake Store - Riesiger Datenspeicher für Big Data-Analyseworkloads
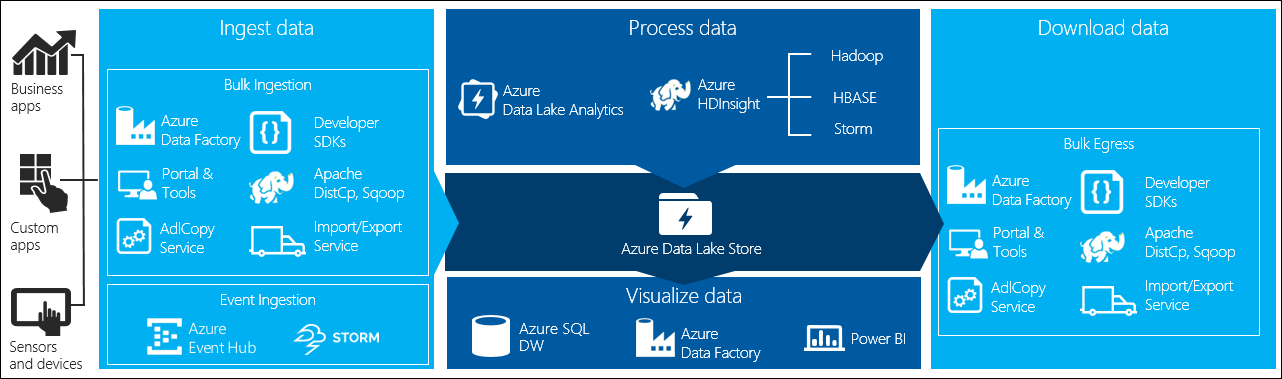
Der Azure Data Lake Store ist ein hochgradig skalierbares Repository, das für Big Data-Analyseworkloads optimiert ist.
Der Data Lake Store bietet eine Basis für unternehmensbezogene Big Data Anwendungen mit der Unterstützung für die Erfassung, Verarbeitung und Analyse, als Quelle und Senke von, sowie die Auswertung und Visualisierung von strukturierten, teilweise strukturierten und unstrukturierten Daten.
Neben der Unterstützung von verschiedenen APIs, SDKs und Schnittstellen, ist der Data Lake Store als Dienst in Azure integriert, so dass andere Azure-Dienste wie HDInsight, Data Lake Analytics, Stream Analytics, Data Factory usw. den Store als Repository sowie Datenquelle und Senke verwenden können.
Mit HDInsight „öffnet“ sich dabei die Hadoop und Apache-Welt und mit der Azure Data Factory (salopp gesagt) alles andere.
Die Kosten des Dienstes hängen von der Menge der gespeicherten Daten, vom Volumen und Größe der Transaktionen sowie den ausgehenden Datenübertragungen ab.
Durch die Verbindung mit den anderen Azure-Datendiensten, wie zum Beispiel der Data Factory und Tools wie dem im SQL-Server integrierten Polybase, bieten sich nahezu unbegrenzte Möglichkeiten für alle Arten von Big Data Anwendungen. Es wird daher eher schwierig die geeignetsten Dienste und Architekturen zu identifizieren.
Und, leider steht der Data Lake Store (noch?) nicht in der nach dem Datentreuhändermodell verwalteten Cloud von Azure in Deutschland zur Verfügung, sondern für Europa bisher nur in der Region Nordeuropa (Irland).
• Data Lake Analytics - Analyse im Data Lake
Verteilter Analysedienst zur vereinfachten Analyse von Big Data
Der Azure Dienst Data Lake Analytics bietet eine Schnittstelle zur Ausführung von Programmen zur Verarbeitung, Transformation und Analyse von Big Data und Daten im Data Lake Store.
Unterstützt werden (z.Zt.) die Sprachen U-SQL, R, Python und .NET, wobei U-SQL eine Abfragesprache darstellt, bei der die bekannte deklarative SQL-Sprache mit den Ausdrücken von C# kombiniert wird. Entwickeln lassen sich die U-SQL Anwendungen über bereitgestellte Tools in Visual Studio. Ausführen lassen sich die entwickelten Anwendungen – wie z. B. Analysen, ETL-Strecken, Abfragen, Machine Learning u.ä. – je nach Workload hochgradig parallelisiert bei einer dynamischen Skalierung in der Cloud. Es wird dabei nur die in Anspruch genommene Verarbeitungsleistung nach Minuten berechnet.
Der Dienst ist für die Arbeit mit dem Azure Data Lake optimiert. Er kann aber auch mit dem Azure Blob Storage und der Azure SQL-Datenbank kombiniert werden. Allerdings gilt auch hier, wie beim Data Lake Store bereits erwähnt, dass der Dienst (noch) nicht in der besonders verwalteten und geschützten Cloud in Deutschland zur Verfügung steht.
• Azure Analysis Services - Datenanalysen in der Cloud
SQL Server's Analysis Service für die Cloud
Die Azure Analysis Services ist eines der jüngsten Dienste in Azure und befindet sich noch in der Previewphase.
Während der bereits genannte Dienst Azure Data Lake Analytics gezielt auf den Azure Data Lake und damit auf Big Data Analysen mit hohem Workload ausgerichtet ist, ist der neue Dienst Azure Analysis Service eher ein Pendant zum SQL Server Analysis Service (SSAS) für die Cloud mit Anbindung an lokale Datenquellen und bekannte Clientanwendungen wie Power BI, Excel und die Reporting Services.
Da der Dienst von den Analysis Services des SQL Server abgeleitet ist, ist er auch mit vielen Features aus der SSAS Welt kompatibel. Zusätzlich arbeiten die Azure Analysis Services mit vielen anderen Azure-Diensten zusammen und ermöglichen so die Erstellung komplexer Analyselösungen nicht nur für die Cloud, sondern auch für hybride Datenmodelle.
Die tabellarischen Datenmodelle können direkt über das Azure-Portal erstellt werden oder aus vorhandenen Datenmodellen aus SSAS in den Dienst migriert werden. Hybride Datenmodelle können über lokale Datengateways angebunden werden. 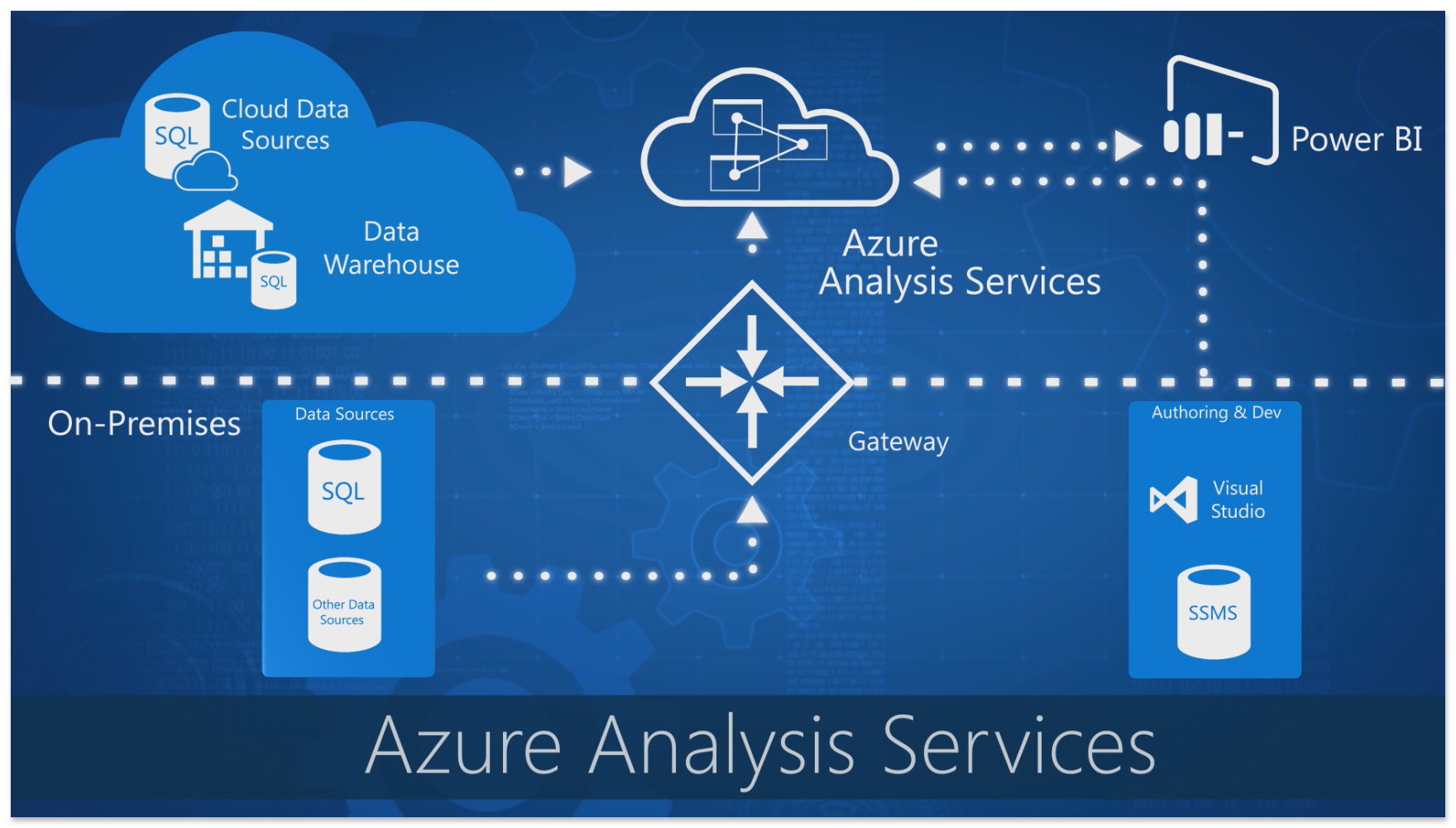
Auch ist der Dienst in die SQL Server Data Tools für Visual Studio und das SQL Server Management Studio angebunden und integriert. Die Erstellung, Verwaltung und Bereitstellung der Datenmodelle erfolgt daher nahezu identisch wie auf einem lokalen Server mit SSAS auch.
Wie erwähnt befindet sich der Dienst noch in der Previewphase und wird noch laufend ausgebaut, was auch die unterstützten Datenquellen betrifft. Die Liste der unterstützten lokalen Datenquellen ist schon recht lang, während sie sich für die Cloud-Datenquellen derzeit noch auf die Azure Blob Storage, die Azure SQL Datenbank und das Azure Data Warehouse beschränkt.
Je nach erforderlicher Verarbeitungsleistung, QPUs (Query Processing Unit) und Speichergröße werden verschiedene Tarife und Preismodelle angeboten. Der Dienst wird bereits in beiden europäischen Azure-Regionen (Norden und Westen) angeboten, allerdings noch nicht in der Deutschland-Cloud.
• Azure Data Catalog - Verwalten von Unternehmensdatenbeständen
Repository für Unternehmensdaten
Der Azure Data Catalog ist ein vollständig verwalteter Dienst, der als Repository und Metadatenspeicher für die verwendeten Unternehmensdatenquellen dient.
In Anbetracht der derzeit rasant steigenden Anzahl an Datenquellen und Assets, bedingt durch die Cloud, hybride Datenmodelle, IoT und dergleichen, ist der Data Catalog eine nahezu erzwungene Notwendigkeit.
Es können sämtliche Benutzer – von Analysten über Data Scientists bis hin zu Entwicklern – Datenquellen und Assets registrieren, ermitteln, verstehen und nutzen. Im Daten-Katalog können Kommentare und Metadaten gesammelt werden, um nicht dokumentiertes Wissen zu erfassen, Licht ins Dunkel der verwendeten Daten und Datenquellen zu bringen und einen zentralen Zugriff auf dieses Wissen zu ermöglichen.
Im Allgemeinen werden der Name, Typ und Beschreibung der Datenobjekte sowie Namen, Datentyp und Beschreibung von Attributen und Entitäten neben den spezifischen Eigenschaften je nach Datenquelle gespeichert. Zusätzlich ist es möglich Beispieldatensätze und aggregierte Informationen wie zum Beispiel die Größe von Tabellen oder Mindest-, Höchst- oder Durchschnittswerte mit abzuspeichern, sowie Informationen, wie auf die registrierten Datenassets zugegriffen werden kann.
Der Dienst wird in einer kostenlosen Edition mit einer Verwaltung von bis zu 5.000 Objekten angeboten. Darüber hinaus fallen Kosten pro Benutzer und Monat an. Ähnlich wohl aller neuen Dienste, steht der Datenkatalog noch nicht in der deutschen Cloud zur Verfügung sondern in Europa Nord und West.